
GraphQL
GraphQL is a query language for APIs and a runtime for fulfilling those queries with existing data.. It is an API standard that provides a more efficient, powerful and flexible alternative to REST. GraphQL was developed and open-sourced by Facebook in 2015 and is now maintained by a large community of companies and individuals from all over the world.
At its core, GraphQL enables declarative data fetching where a client can specify exactly what data it needs from an API. Instead of multiple endpoints that return fixed data structures, a GraphQL server only exposes a single endpoint and responds with precisely the data a client asked for. Another advantage lies in the fact that you can evolve your APIs without versioning, because you can add newer fields and types, or deprecate aging fields without impacting existing queries.
GraphQL provides a concise way to define a GraphQL schema with a well-structured syntax that is officially part of the GraphQL specification. It uses its own language for defining schemas, known as the GraphQL Schema Definition Language (SDL). SDL is both intuitive and easy to use while remaining highly powerful and expressive. Schema definitions are sometimes also called IDL (Interface Definition Language) or SDL (Schema Definition Language).
To perform model-first design of a GraphQL API with Hackolade Studio, you must first download the GraphQL plugin. This plugin is strictly compliant with the GraphQL specification.
Creating APIs is not easy! And creating a GraphQL SDL (Schema Designing Language) in a design-first approach can be tedious at best, and often error-prone and frustrating... Hackolade Studio takes a graphical and schema-centric approach so you can focus on the content of queries and responses. The application also assists with all the metadata to produce validated GraphQL SDL files. You can also reverse-engineer existing GraphQL SDL to produce a graphical representation of your APIs.
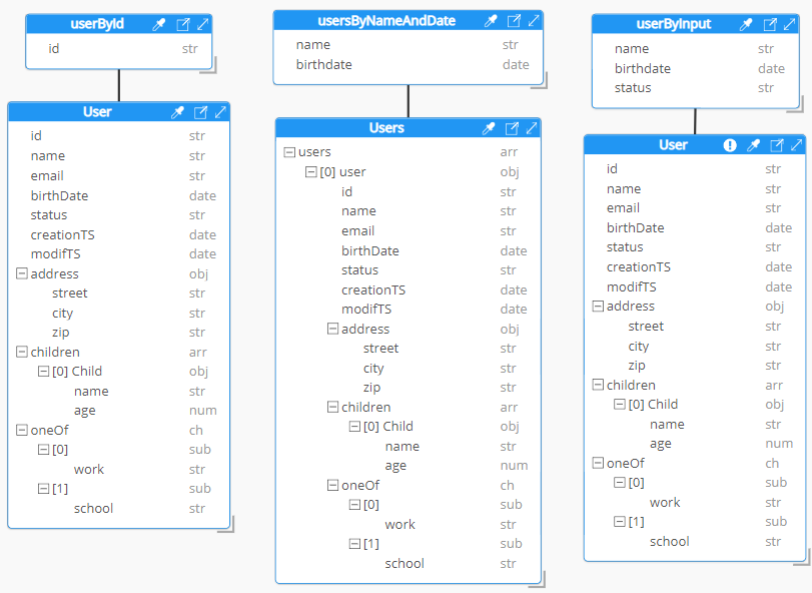
A notable differentiator versus all the existing tools in the GraphQL ecosystem is the Hackolade patent-pending nested representation in an entity-relationships diagram of relationships between types. Our drastically different visualization approach is anchored in the fact that both queries and responses are done using JSON with nested objects, regardless of whether the data source is relational or not. All current tools representing GraphQL schemas stick to a flat and relational visualization, for example
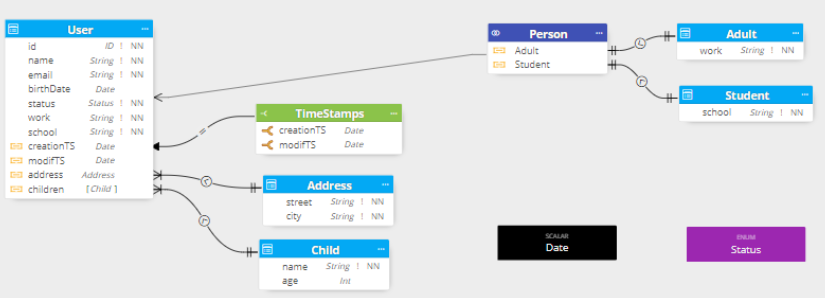
While this visualization may be structured with some correlation to the SDL syntax and the relational structures. But there are several issues with his visualization:
- it seems acceptable for super simple models, but it quickly become hard to read with larger models. In other words, it does not scale.
- it is hard for users to relate the payload being exchanged in the API to the schema SDL
- if the source is NoSQL, the denormalized data source is normalized to fit the SDL syntax
Instead, Hackolade Studio shows the above model in this way, where one single entity box represents the structure of a single end point:
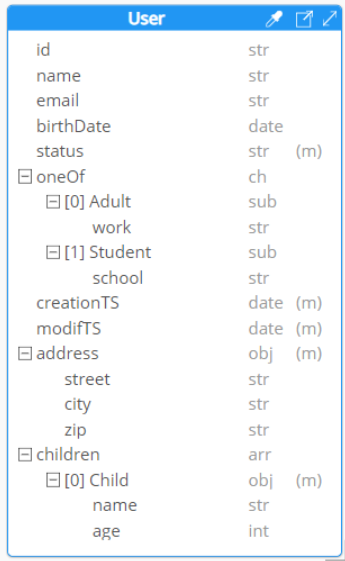
It is easy to see how a diagram becomes naturally more scalable and user-friendly to read and interpret.
Hackolade Studio was specially adapted to support the API design for GraphQL, including all the necessary metadata for the API, the type definitions, as well as the root types with their arguments for queries, mutations, and subscriptions. The application closely follows the terminology of the specification. The graphical tool puts the focus on what really matters in an API: the schema of the information being exchanged between systems. At the same time, it provides assistance to modelers and does not require mastery of the GraphQL SDL syntax. It generates validated SDL files that are syntactically correct and compatible with the specification thereby greatly improving productivity, consistency, and quality.
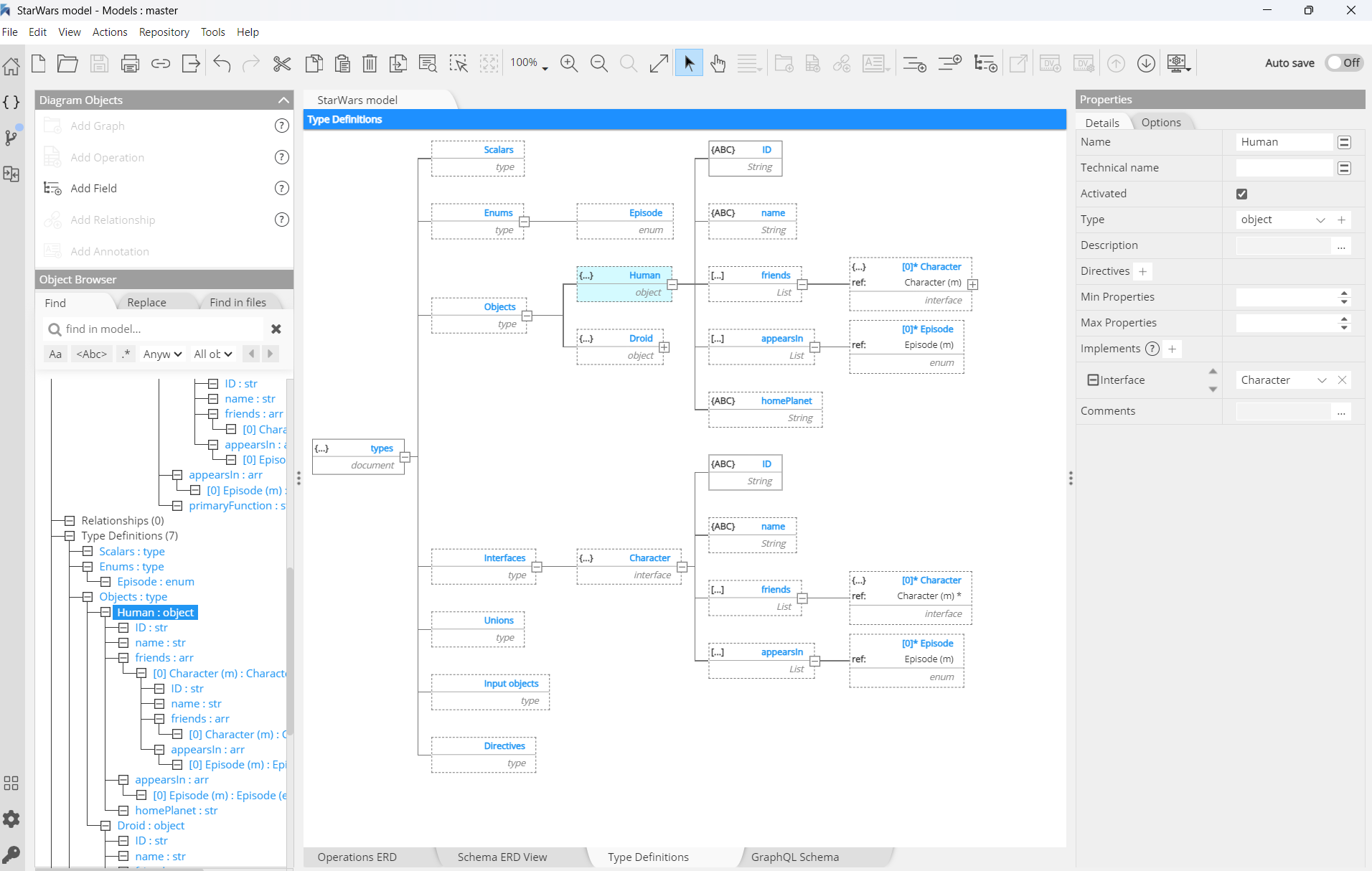
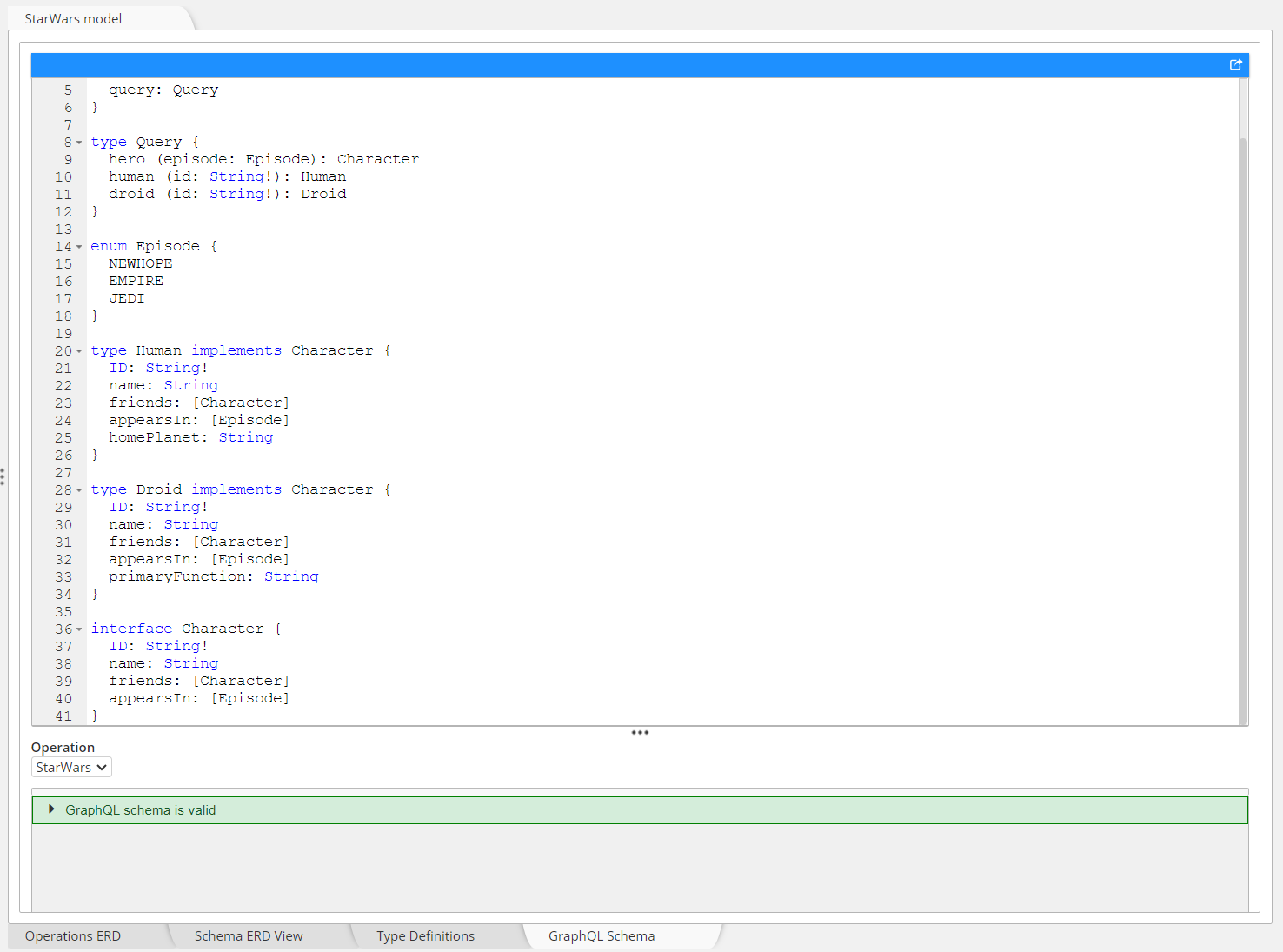
The diagram below shows the structure of a StarWars schema used to illustrate the GraphQL specification:
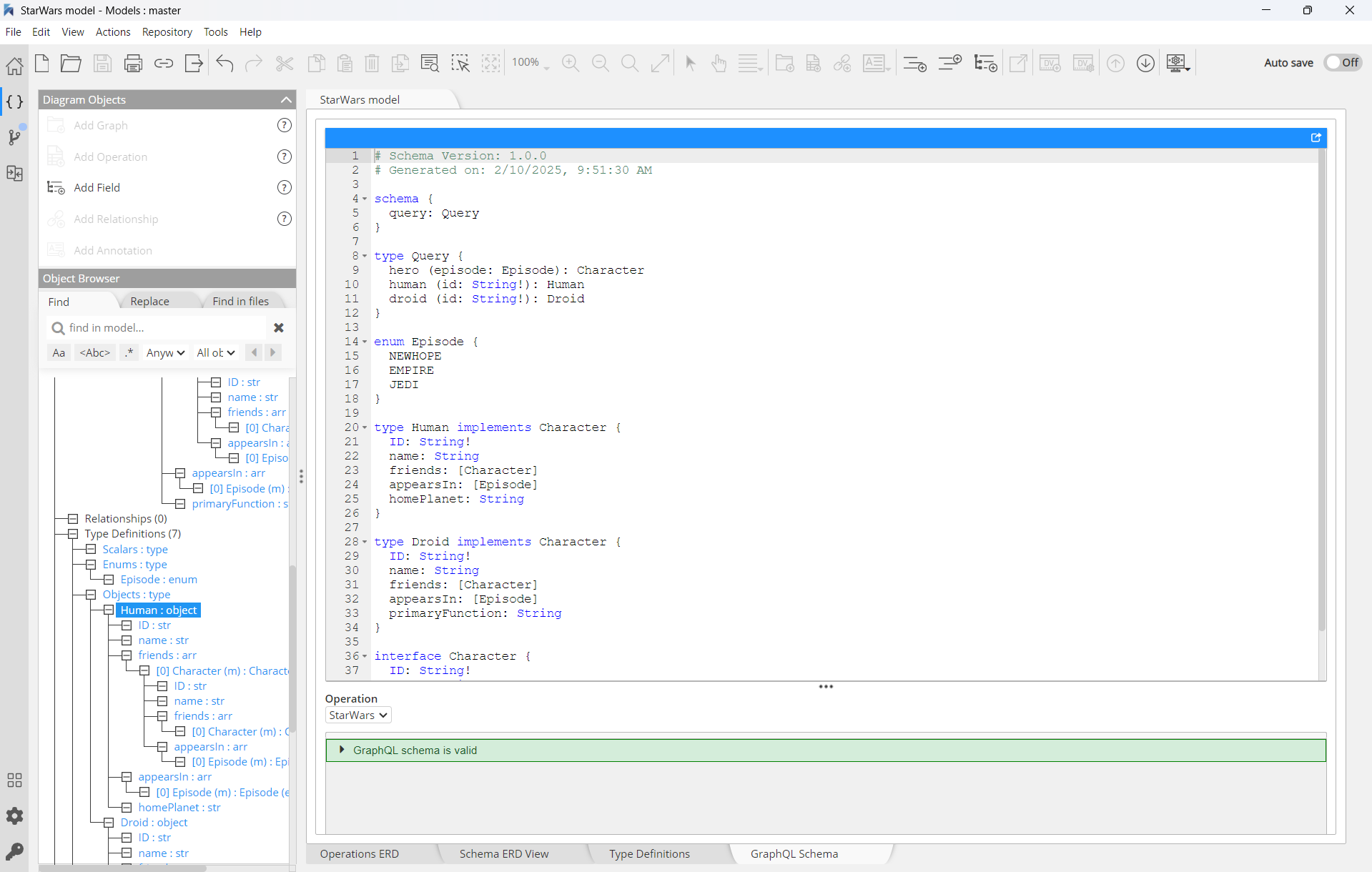
and the resulting SDL, syntactically correct and automatically generated by the tool:
GraphQL SDL specification summary
Every GraphQL server has two core parts that determine how it works: a schema and resolve functions.
The schema serves as a blueprint for the data that can be retrieved through the GraphQL server. It specifies the queries that clients are allowed to make, the types of data available, and the relationships between those types.
While the schema defines query permissions and type relationships, it does not include the source of the data for each type. This responsibility falls on server resolve functions. Since resolve functions go beyond the scope of a data modeling tool, we won’t cover them here.
Here are some principles of a GraphQL schema:
- Types: the schema specifies the different types of data that can be requested.
- Fields: each type includes a set of fields that define the specific pieces of data available. These fields can be various data types, such as strings, integers, or other complex objects.
- Arguments: fields can take arguments, allowing for more precise data retrieval. For example, an orderBy argument can determine the sorting order of returned posts.
- Queries: the schema establishes the entry points for fetching data through queries, which are used to retrieve information from a GraphQL server.
- Mutations: it also defines mutations, which are operations that modify data on the server, such as creating, updating, or deleting records.
- Resolvers: the schema includes resolver functions responsible for fetching data for each field. When a GraphQL query runs, the corresponding resolver is triggered to retrieve the required information.
The syntax for writing schemas is called Schema Definition Language (SDL). Here is an example of how we can use the SDL to define a simple type called Person:
type Person {
name: String!
age: Int!
}
This type has two fields, they’re called name and age and are respectively of type String and Int. The exclamation mark ("!")following the type means that this field is required.
It’s also possible to express relationships between types. In the example of a blogging application, a Person could be associated with a Post:
type Post {
title: String!
author: Person!
}
Conversely, the other end of the relationship needs to be placed on the Person type
type Person {
name: String!
age: Int!
posts: [Post!]!
}
Note that there is a one-to-many-relationship between Person and Post since the posts field on Person is actually an array (or list) of posts, represented by square brackets ("[...]")
Operations
The Query type in a GraphQL schema is similar to the "operations" (i.e., requests) defined in an OpenAPI (formerly known as Swagger) specification. They are entry points for queries, mutations, and subscriptions.
In an OpenAPI specification, an "operation" represents a request that can be made to a server, along with the parameters and response that are expected for the request. An operation is typically defined as a combination of a HTTP method (e.g., GET, POST, PUT, etc.) and a path (e.g., "/users").
In a GraphQL schema, the Query type serves a similar purpose, but it is defined in a more flexible and expressive way. Instead of using HTTP methods and paths to define operations, a GraphQL schema uses fields and arguments to define the data that can be queried.
Fetching data with queries
When working with REST APIs, data is loaded from specific endpoints. Each endpoint has a clearly defined structure of the information that it returns. This means that the data requirements of a client are effectively encoded in the URL that it connects to.
The approach taken in GraphQL is radically different. Instead of having multiple endpoints that return fixed data structures, GraphQL APIs typically only expose a single endpoint. This works because the structure of the data that’s returned is not fixed. Instead, it’s completely flexible and lets the client decide what data is actually needed.
That means that the client needs to send more information to the server to express its data needs - this information is called a query.
One of the major advantages of GraphQL is that it allows for naturally querying nested information. For example, if you wanted to load all the posts that a Person has written, you could simply follow the structure of your types to request this information:
{
allPersons {
name
age
posts {
title
}
}
}
GraphQL allows a client to specify exactly what data it needs from the API. In the example above, a user can adapt the query to only return the relevant information. If the field age in the example above is not relevant for this query, then the query could be adjusted so that the field age is not included in the response:
{
allPersons {
name
posts {
title
}
}
}
Queries with Arguments
In GraphQL, each field can have zero or more arguments if that’s specified in the schema. For example, the allPersons field could have a last parameter to only return up to a specific number of persons. Here’s what a corresponding query would look like:
{
allPersons(last: 2) {
name
}
}
The allPersons field in this query is called the root field of the query. Everything that follows the root field, is called the payload of the query.
Here are some examples of common arguments that are used in a "Query" type:
- id: A unique identifier for a specific object.
- limit: The maximum number of results to return.
- offset: The number of results to skip before returning results.
- sort: The field or fields to sort the results by.
- order: The order in which to sort the results (e.g. ascending or descending).
- filter: A set of conditions to filter the results by.
- find: Used to search for specific data based on specific criteria, typically a user input.
There can be others like: where, distinct_on, order_by, etc.
mutation {
createPerson(name: "Bob", age: 36) {
name
age
}
}
Notice that the mutation also has a root field - in this case it’s called createPerson.
It is possible to also query information when sending mutations, which can be a very powerful tool to retrieve new information from the server in a single roundtrip!
Real-time Updates with Subscriptions
Another important requirement for many applications today is to have a real-time connection to the server in order to get immediately informed about important events. For this use case, GraphQL offers the concept of subscriptions.
When a client subscribes to an event, it will initiate and hold a steady connection to the server. Whenever that particular event then actually happens, the server pushes the corresponding data to the client. Unlike queries and mutations that follow a typical “request-response-cycle”, subscriptions represent a stream of data sent over to the client.
Subscriptions are declared in SDLs as a root type in the schema alongside the query and mutation types. Here is an example of how subscriptions can be declared in a GraphQL schema:
type Subscription {
newMessage: Message
}
In this example, the Subscription type has a field called newMessage that returns a Message type. This means that the client can subscribe to notifications for new messages by using this field in a subscription query.
Subscription fields can also accept arguments in the same way that query and mutation fields do. For example:
type Subscription {
newMessage(roomId: ID!): Message
}
In this example, the newMessage field accepts a required argument called roomId. This allows the client to specify which room for which they want to subscribe to notifications.
Subscriptions can also use the @ directives to specify conditions that must be met before the subscription is triggered. For example:
type Subscription {
newMessage(roomId: ID!): Message @auth
}
In this example, the @auth directive specifies that the client must be authenticated in order to subscribe to notifications for new messages in the specified room.
Structure of an SDL
Here is a list of keywords used in the GraphQL SDL to define a GraphQL schema:
- Schema: defines the root types of a GraphQL API, which serve as entry points. These include Query, Mutation, and Subscription.
- Type: specifies an object type in the schema, representing a collection of fields that can be queried together.
- Interface: declares a set of fields that multiple object types can implement, ensuring consistency across different types.
- Union: represents a union type, allowing a field to return multiple possible object types without sharing common fields.
- Scalar: defines a custom scalar type beyond the built-in types like String, Int, Float, Boolean, and ID.
- Enum: creates an enumeration type, which is a predefined set of named values that a field can return.
- Input: describes an input object type used for passing structured arguments in mutations.
- Extend: expands an existing type or interface by adding new fields or functionality.
- Directive: defines a custom directive to modify schema behavior. Directives can be applied to fields, arguments, and other schema elements, with the server passing them to the client for interpretation.
Build a GraphQL SDL with Hackolade Studio
A GraphQL model in Hackolade Studio can be built in different ways:
- forward-engineering a Hackolade Studio model of any target, using the function for model-driven API generation (TBA)
- deriving from a Polyglot model (TBA)
- reverse-engineering an artifact like DDL or JSON-Schema (TBA)
- reverse-engineer from an Excel template (TBA)
- building the model from a blank page.
We focus here on this last option, as it provides a good understanding for how the plugin operates.
Type definitions
The core of any GraphQL implementation is a definition of the object types it can return, structured within the GraphQL type system and outlined in the GraphQL schema. Let's build together a GraphQL model in Hackolade Studio, based on a StarWars example. We start with so-called "non-root types".
Non-root types in GraphQL are types that define the structure of data but are not directly used as entry points for queries, mutations, or subscriptions.
Root types, on the other hand, serve as the entry points of a GraphQL API and include Query, Mutation, and Subscription, which define how clients interact with the schema. We describe in the next section how to build root type operations or entry points.
Type definitions are created in the corresponding lower tab of the central pane

THe different types that you can define are proposed in a tree view:
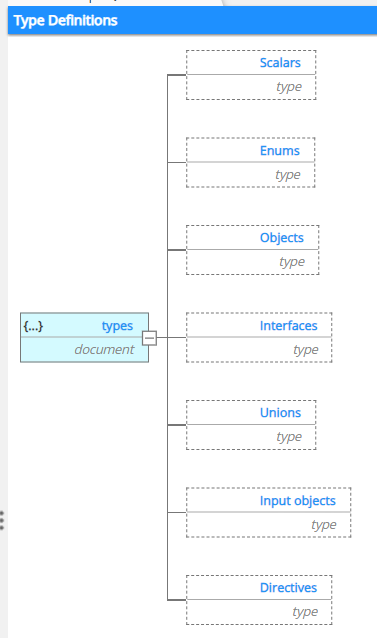
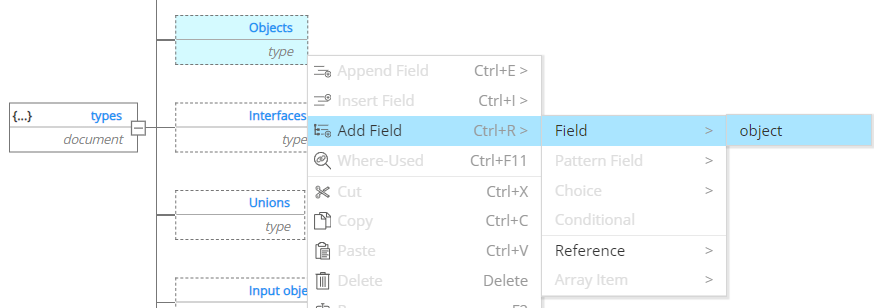
To build your types, you may use the Actions menu, the toolbar icons, or the contextual menu either in the Object Browser on the left or in the Central Pane. In this example, we use the contextual menu which filters options to show only the appropriate one(s) for the type you're creating or enhancing.
Let's create the first type:
The type Human is an object type, and that object contains a field with the label name which has a data type Sting:
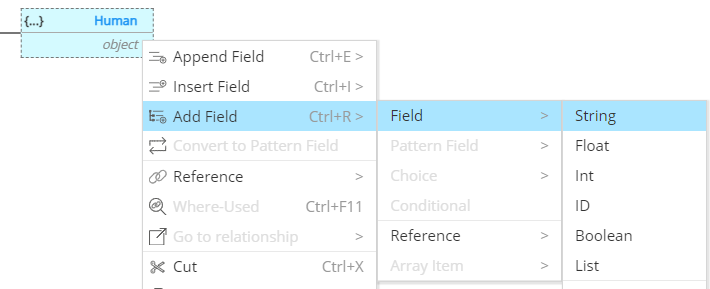
We can easily add an ID field and a homePlanet field:
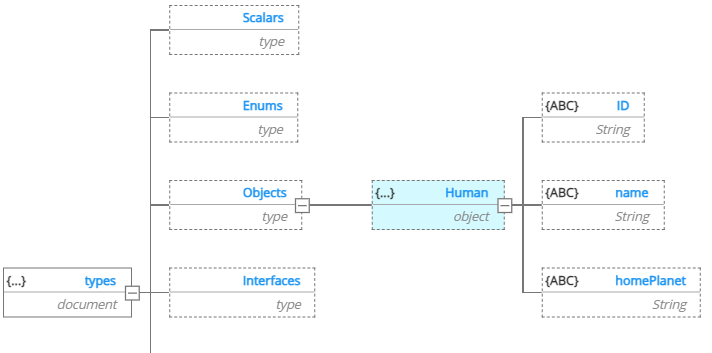
In the next step, we need to define a reusable Enum, then reference it in the Human object type:
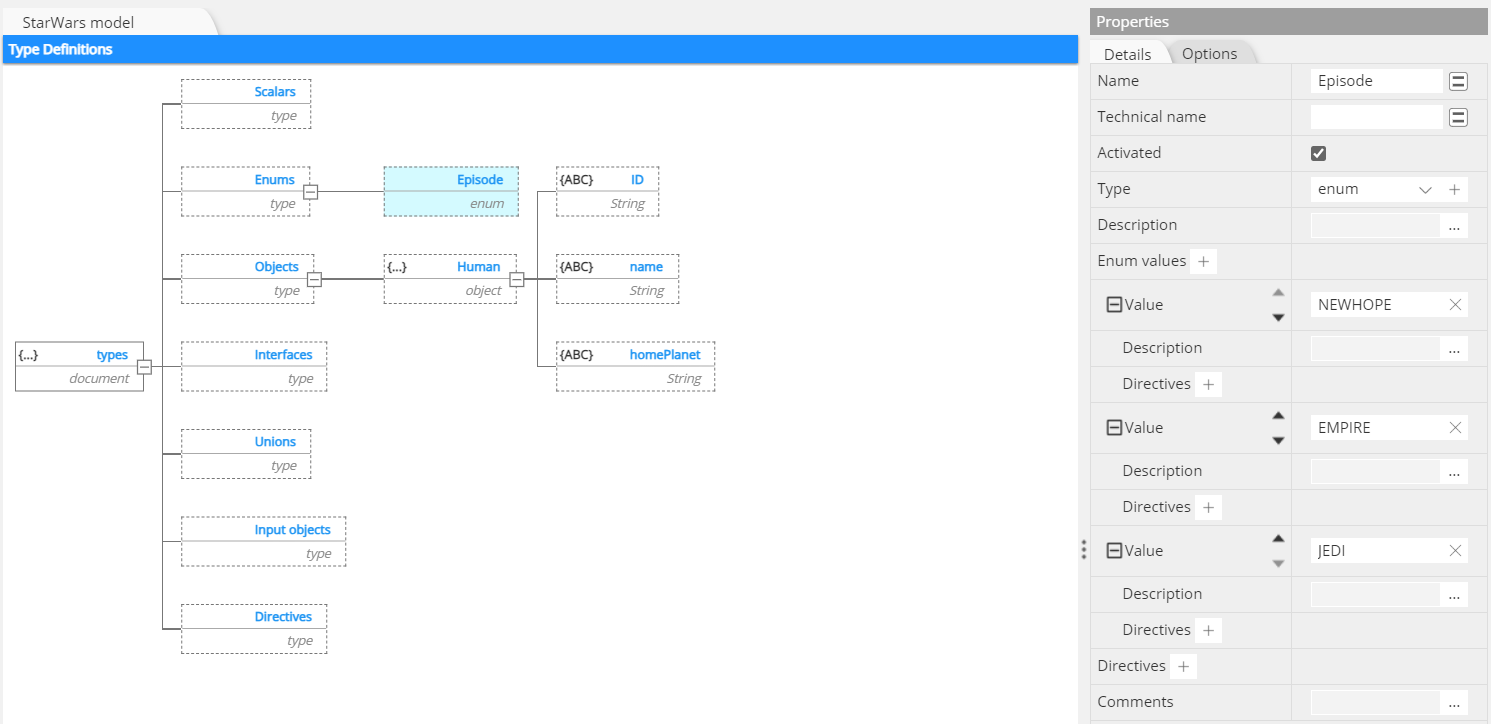
To create a reference to the newly created Enum is easy. But before we do that, there is a subtlety here. A Human can appear in more than one episode. So it is necessary here to first create a list, the represent the 1-to-n relationship between Human and Episodes:
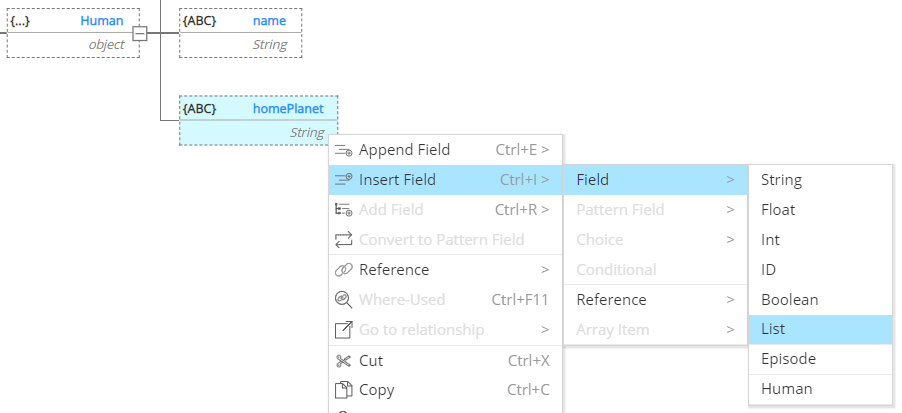
Then replace the list item by a reference to the previously defined Episode Enum:
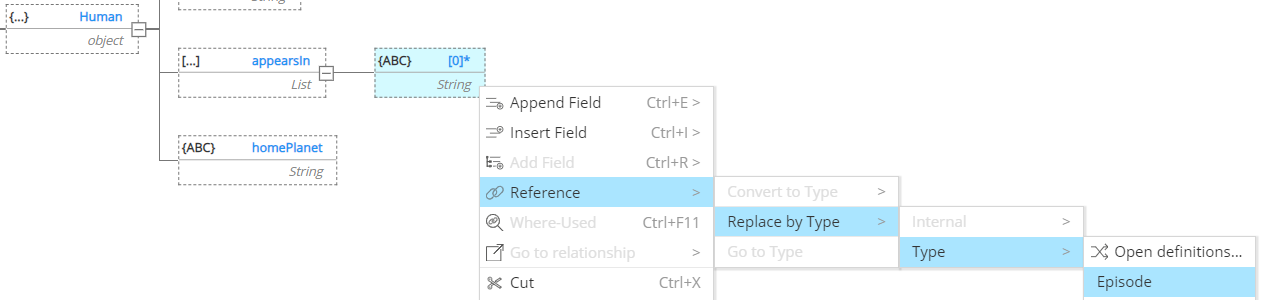
and it results in this structure:
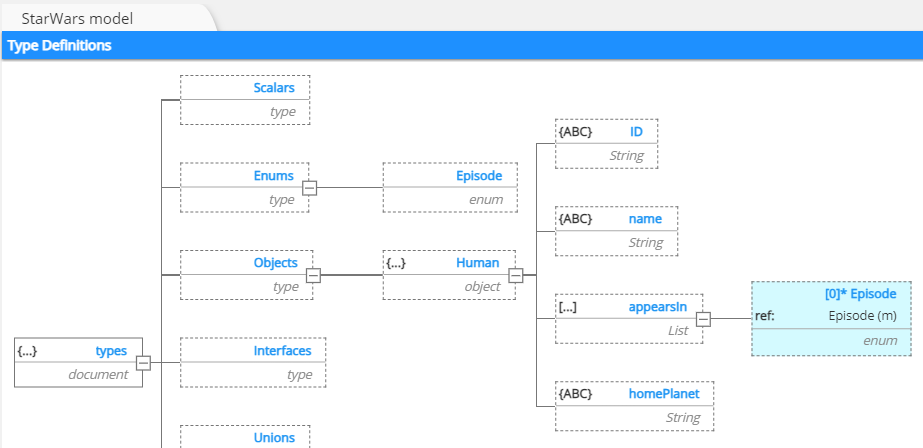
Most importantly, you can see that Hackolade Studio automatically generates the syntactically correct SDL in the GraphQL Schema lower tab of the central pane:
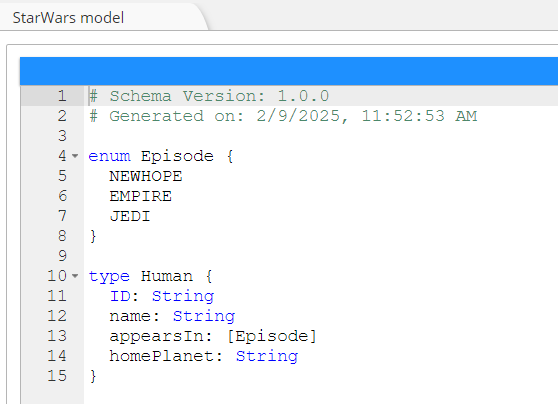
In the above process, we simply added new fields to the Human object. That's fine. But in some cases, you may want to leverage a reusable structure. We're already doing that by referencing the Enum Episode. And referencing can be used in many circumstances.
Referencing any non-root type means using that type as a subobject in your own type definition, but without the possibility of making deviations.
But there is another possibility, which implements an interface. Implementing an interface means defining an object type that adheres to the interface by including all its required fields, ensuring consistency across multiple object types. It also allows you to query these types using the interface as a common denominator.
In the StarWars example, we want to create a Droid type which shares the first 4 fields with the type Human. Instead of retyping multiple types, or copying and pasting, let's build from the start a construct that can be reused to boost consistency and quality without some of the flexibility restrictions of referencing.
We create here the Character interface with the common fields:
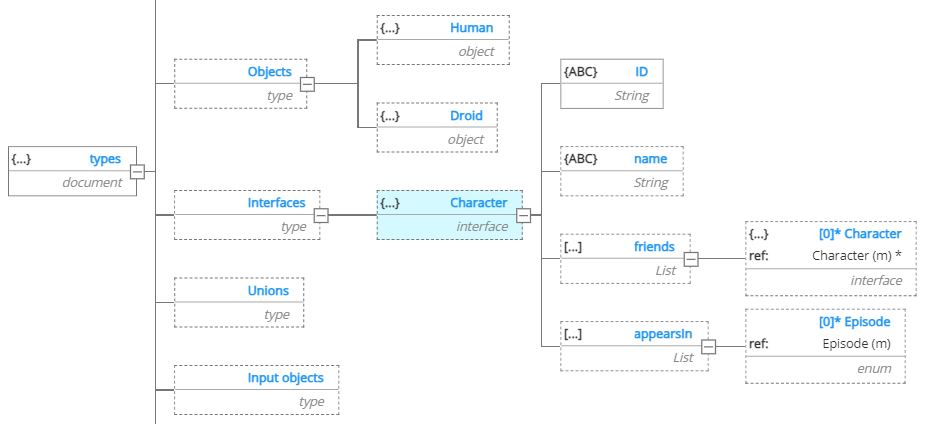
Then for the Human object type, we can select the Implements of the Character interface:
then add any additional field that might be specific to the Human object type but not common with any other. The process of selecting an interface to implement performs a copy action for all of the fields of the interface at the time of the action:
This action results in the following structure:
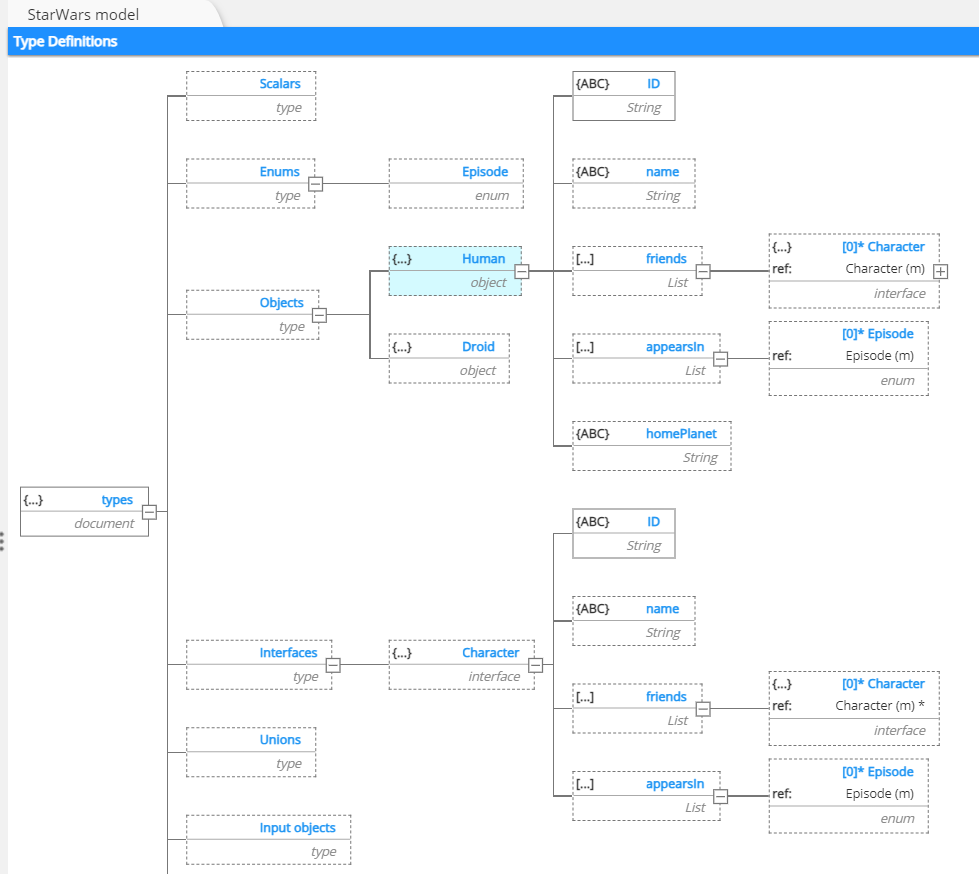
We can then do the same for the Droid type, then see the results in the following auto-generated SDL:
Root types operations entry points
It is in the Operations ERD lower tab of the central pane that you define the graphical and schema-centric entry points for your queries, mutations, and subscriptions.
The idea is to graphically display the input arguments and the payload structure of the response. This graphical representation makes it more obvious to users how to query as well as the expected response:
This feature is currently evolving rapidly. This documentation page will be enriched when the feature matures. In the meantime, it is easy to create a graph and operation by clicking the Add Graph button in the Diagram Objects pane on the left of the workspace:
In the StarWars example, we want to define a query hero to return the Character who is the hero of the trilogy, and specify an optional argument to fetch the hero of a specific episode:
You start by adding the query response that you expect for the operation:
Then you define the input argument for your query:
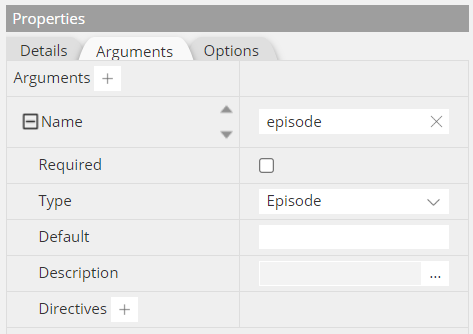
The argument can be an input field, an input object, an object type, or an interface. And arguments can be used for input as well as output.
It results in this graphical representation of the operation:

Currently, Hackolade Studio does not yet support GraphQL federation. But in preparation for it, you should include a "container" for each graph in your model. Alternatively you could have separate models for each graph.
Forward-engineer GraphQL Schema Definition Language
You may view the GraphQL Schema in the corresponding lower tab of the central pane. The GraphQL-compliant output can be copied and pasted into the tool of your choice within your technology stack, for example Apollo Studio, as described below. Or you may generate a SDL file with the .graphql extension, so it can be imported into other tools, such as Postman, as described below.
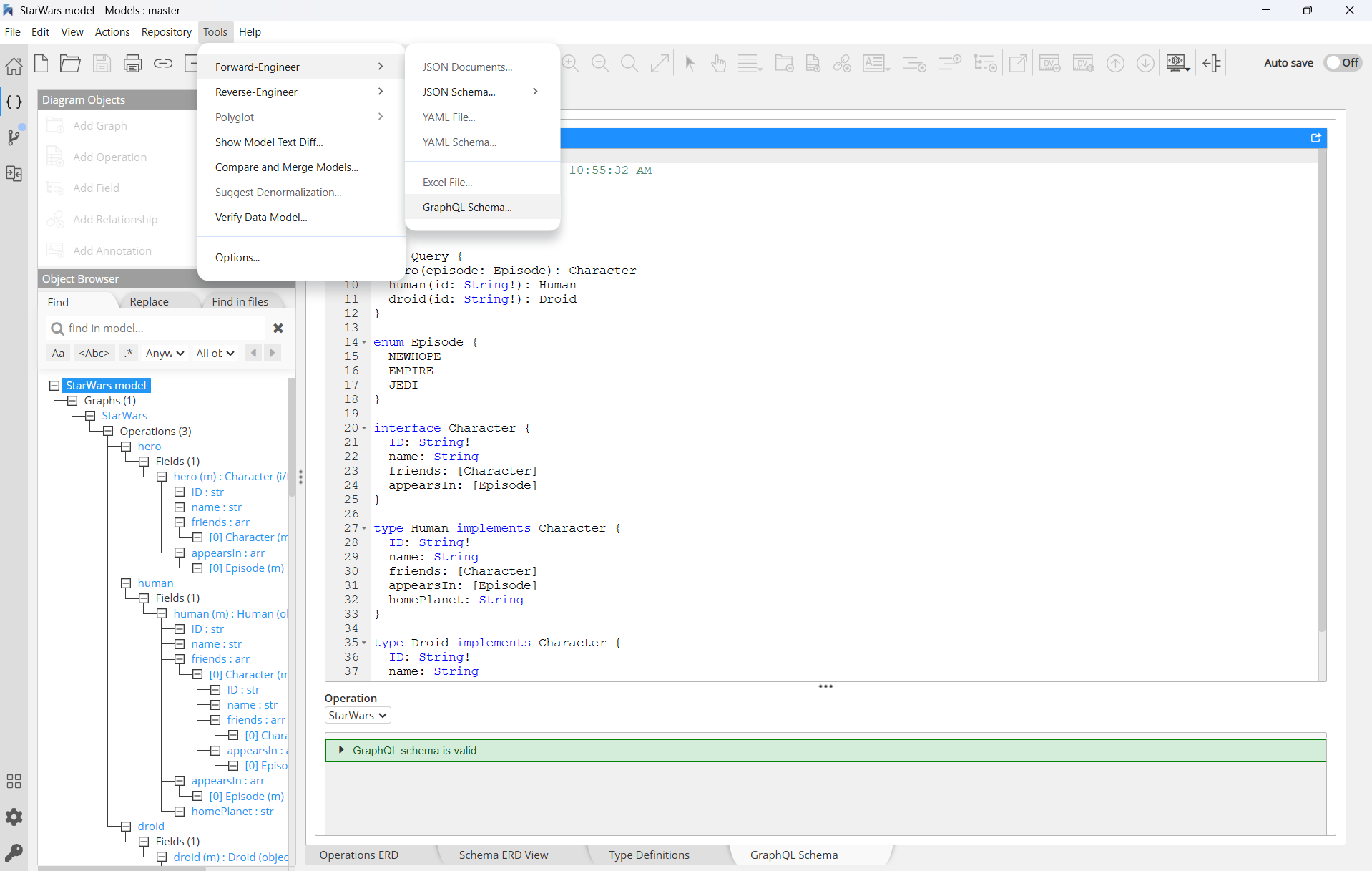
Reverse-engineer an SDL file
It is possible to import (reverse-engineer) an existing GraphQL API into Hackolade Studio, either by choosing an SDL file, or by performing an introspection from a GraphQL endpoint.
Schema Definition Language files are typically stored in text files with the extension .graphql (sometimes .gql)
Perform a schema introspection from a URL
Introspection is a powerful feature of GraphQL that allows to dynamically discover and explore the schema of a GraphQL API. The schema can be examined to get information about its types, fields, and other elements. In GraphQL, this is done by querying the __schema and __type introspection fields, which are provided by the GraphQL server.
Hackolade Studio allows users to create a connection, with authentication if necessary, to
How does the Hackolade Studio plugin for GraphQL compare with Apollo Studio?
The Apollo page for GraphQL Schema Basics is a different version of the information you can find above. But instead of having to type it all up without making any typos, Hackolade Studio provides a way to build your schema with a few click of a mouse. Or better yet, based on an existing target model, or by importing DDLs, etc. As such, it is a great complement to the Apollo suite of tools for GraphQL.
With our GraphQL plugin, we can do much more than design schemas. More on that below in a section below.
If you don't yet have an API endpoint up and running, you may still use the Apollo Studio where you can import the Schema Definition Language SDL file out of Hackolade Studio. When you create a new a new graph, you're first prompted to provide an endpoint. If you provide one that is not accessible, Apollo Studio proposes to upload your schema:
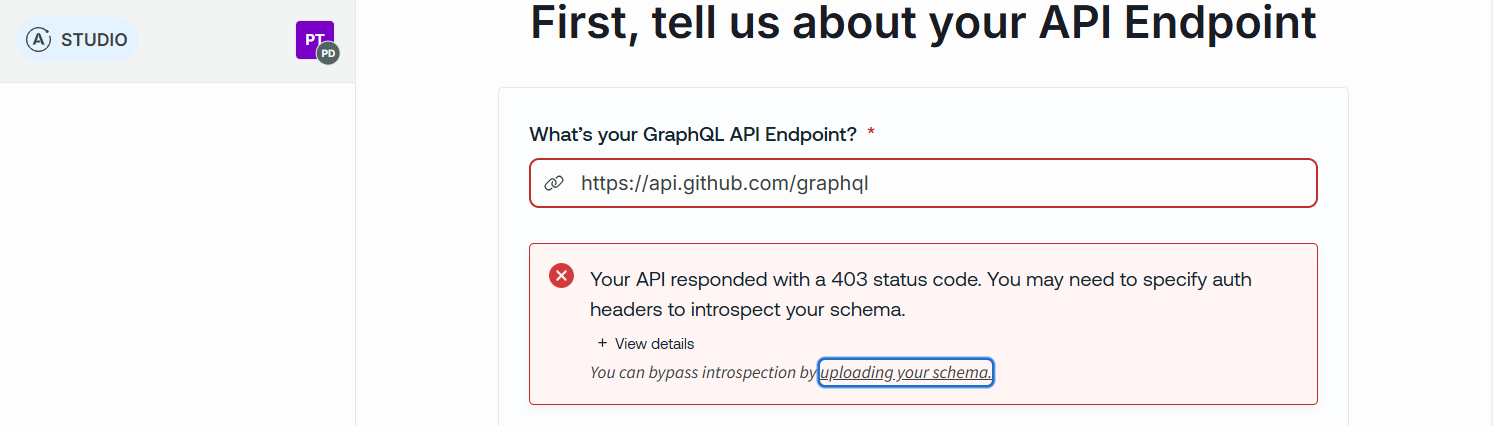
You can simply copy from the Hackolade Studio and paste in the Apollo Studio dialog:
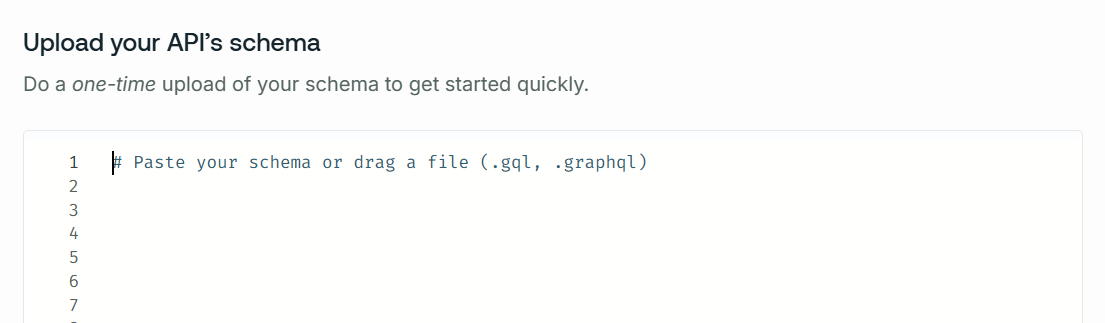
You will then be able to build your queries, mutations, and subscriptions based on the schema you just uploaded. The schema is also visible in the schema tab:
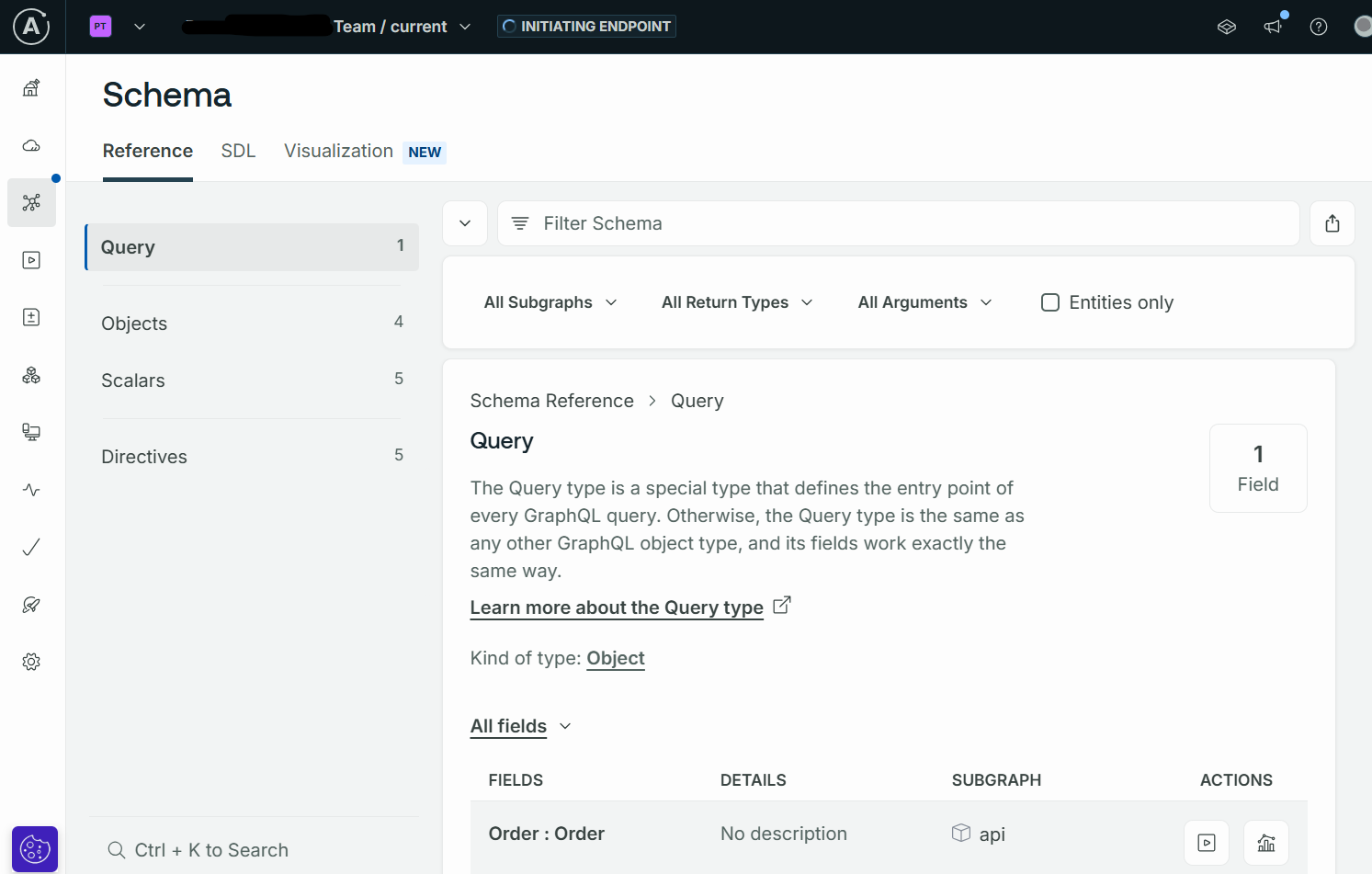
How does the Hackolade Studio plugin for GraphQL compare with Postman?
At Hackolade, we're big fans of Postman. Our solution is a complement to Postman's support of GraphQL with no overlap. Hackolade Studio with its GraphQL plugin is a design tool for GraphQL schemas. Whereas Postman is a client with which you can make GraphQL requests that leverage a schema.
With our GraphQL plugin, we can do much more than design schemas. More on that below in a section below.
A GraphQL schema describes all the data available to clients, the set of operations (queries, mutations, and subscriptions) that can be performed, and how types and fields relate to each other. Hackolade take a schema-centric approach so that you can easily navigate the graph with multiple entry points in your queries, mutations, and subscriptions.
While you may already have existing APIs that you wish to document with Hackolade and publish to data dictionaries and maintain, the added value of Hackolade Studio is the ability to create a schema and discuss it with stakeholders before the server has been built. You can build the GraphQL schema with a few clicks of a mouse, then generate a syntactically correct schema SDL (Schema Definition Language) without any knowledge of the details of the syntax (just like you can build an ERD and the DDL gets generated automatically.) You can forward-engineer the SDL artifact to a .graphql file.
Then, in Postman, you just import the GraphQL schema:
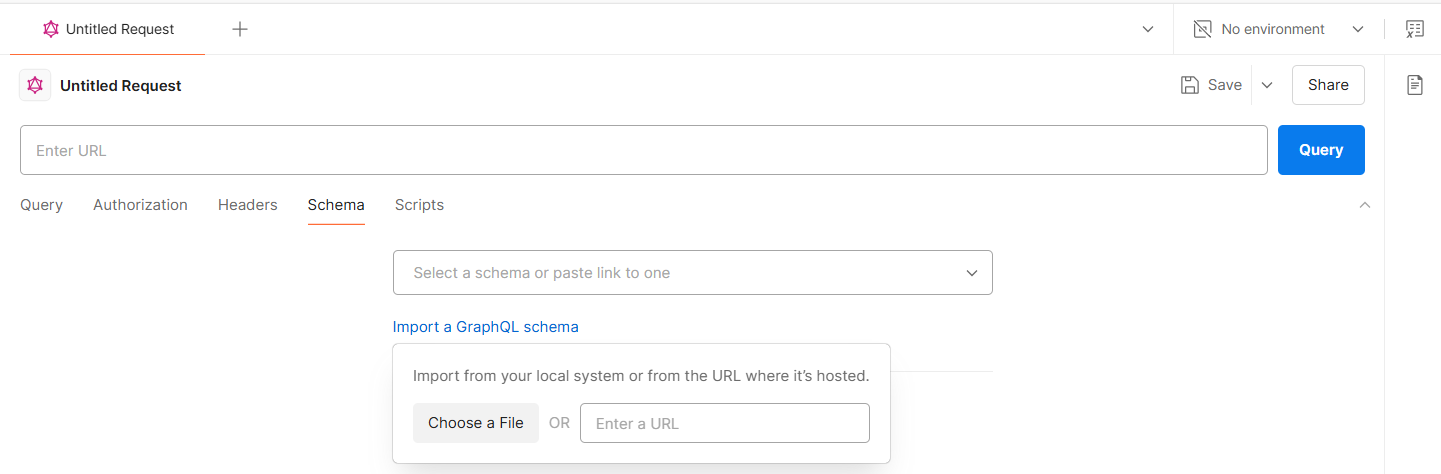
After import, you can easily assemble your queries, mutations, and subscription on the schema created with Hackolade Studio:

Other added value of building GraphQL schemas with Hackolade
Beyond the creation from scratch of GraphQL schemas with Hackolade Studio, the added value of our solution is:
- Use one single tool with harmonized user interface for modeling of data-at-rest and data-in-motion
- Model-driven GraphQL API generation: start from a model in any target, and generate the GraphQL schema file in just a couple of clicks, then keep the target model and the GraphQL models in sync
- Integration with our Polyglot modeling approach so all models can easily be kept in sync
- Publish GraphQL models to data dictionaries
- Command-Line Interface to automate the above
- Etc.