
Data modeling and the AI lifecycle
Artificial Intelligence is a multiplier. It amplifies what an organization is already capable of... as well as what it ignores. It scales whatever foundation it’s applied to. If the underlying processes, data quality, and organizational practices are strong, AI can dramatically improve efficiency, insight, and decision-making. But if those foundations are weak -- messy processes, biased or incomplete data, poor communication -- AI won’t fix them. AI requires orchestra conductors and choreographs more than it requires engineers to operate it.
In particular, AI is only as good as the data it understands. AI built on ungoverned data will yield unpredictable and unreliable outcomes. Without dedicating time and resources to ensure data reliability, you can't expect reliable AI.
There’s a growing illusion that Generative AI can effortlessly produce high-quality data models or database schemas from a single clever prompt. As if deep domain understanding were optional. In reality, this is a textbook case of garbage in, garbage out. Without clear, complete, and contextually accurate input, GenAI will generate structures that may look convincing but lack semantic precision, consistency, and alignment with business realities. The true value of a well-designed data model lies in the careful articulation of concepts, definitions, and relationships -- work that depends on subject-matter expertise, not just syntactic fluency. A vague or incomplete prompt leads the AI to fill in gaps with assumptions, resulting in artifacts that are underwhelming at best and dangerously misleading at worst.
A strong data model keeps AI grounded, ensuring accurate outputs, real-time reasoning, and seamless system integration. Data modeling contributes to better AI by providing a structured framework for organizing, interpreting, and leveraging data effectively. It helps define the relationships between different data elements, ensuring that AI systems can access clean, consistent, and relevant information for training and decision-making. By establishing clear data schemas and reducing ambiguity, data modeling improves the quality and accuracy of machine learning models, reduces bias, enhances interpretability, and enables scalability. Ultimately, it lays the foundation for more intelligent, reliable, and efficient AI systems by aligning data with the goals and logic of AI algorithms.
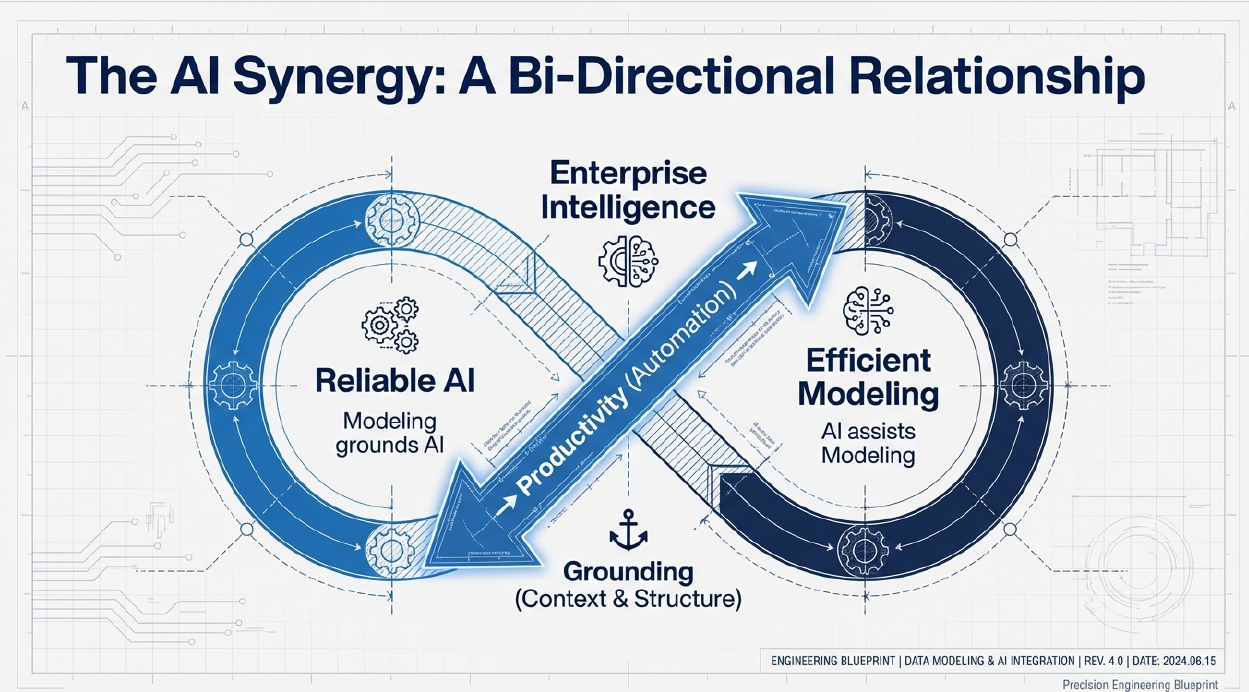
Conversely, AI can contribute to better data modeling by enabling advanced automation and intelligence throughout the modeling lifecycle. The current state of GenAI does not replace the synthesized knowledge of a subject-matter expert. It would take so much effort to create the prompts, that the user might as well specify the details directly in a data model. Nevertheless, we see the significant benefits of intelligent assistance to data modeling, for example to alter about inconsistencies or possible optimization. GenAI can greatly increase the productivity of users, for example by suggesting descriptions and associations with previously defined glossary terms. Or by helping to identify meaning in existing structures that lack proper descriptions.
Today, Hackolade Studio can already reverse-engineer Mermaid ERD code potentially generated by GenAI outside Hackolade Studio. The application will be able to generate Mermaid diagrams from existing Hackolade data models (albeit with some limitations to match Mermaid's own restrictions.) GenAI can be leveraged for metadata enrichment by generating meaningful descriptions for entities and attributes to be edited by subject-matter experts, and by recommending attributes based on industry standards. Furthermore, AI can propose dimensional models optimized from transactional schemas and suggest improvements such as better partition key choices, laying the groundwork for more efficient and standards-aligned data architectures.
AI contributes to better data modeling
AI can contribute to better and more productive data modeling by providing the ability to automate and enhance some aspects of the data modeling process. Currently AI is not yet good enough at understanding the specifics of domains in order to create entire data models. The process requires a human in the loop, as the knowledge by subject-matter experts and data modelers of the nuances of organizations remains too complex for AI to handle. But it can assist in many ways to increase productivity.
It can analyze large and complex datasets to identify hidden patterns, relationships, and anomalies that might be missed by human analysts. AI-driven tools provide intelligent assistance, plus the ability already to perform simpler but tedious tasks. They can recommend optimal data structures, detect inconsistencies, and suggest schema improvements based on usage patterns and historical data. Machine learning algorithms also help in predictive modeling, enabling dynamic and adaptive models that evolve with new data. Additionally, AI can streamline tasks like data cleaning, entity recognition, and metadata generation, making the data modeling process faster, more accurate, and more scalable.
AI implementation must be designed with the understanding that its impact on human performance is asymmetrical: when AI guidance is correct, human performance can improve significantly ), but when AI is confidently wrong, performance can become dramatically worse than without AI).
AI should be used primarily to provide explanations and context rather than final recommendations, and humans must maintain strong mental models of the system to recognize when AI is hallucinating or misleading. Critical guardrails include clear attribution (always knowing whether information comes from a human or AI), built-in explainability features, and ideally explicit signals about AI confidence and limitations. The goal is to use AI as a tool for gathering data and redirecting human attention while keeping humans in the loop for final decisions, especially in novel or complex situations where AI lacks causal models. You may get more details in this article about the ironies of automation and AI.
At Hackolade, we could have easily pursued developing our own Natural Language Processing (NLP) Large Language Models, or Generative Pre-Trained Transformer (GPT) models. However, we’re not driven by a “Not Invented Here” mentality! Our core focus is on data modeling, and there are many brilliant experts out there who specialize in NLP, LLMs, and GPT technologies. Moreover, as highlighted below, we place a premium on security and confidentiality, which is why we prefer if our customers have the freedom to choose and control the technologies they use in this context.
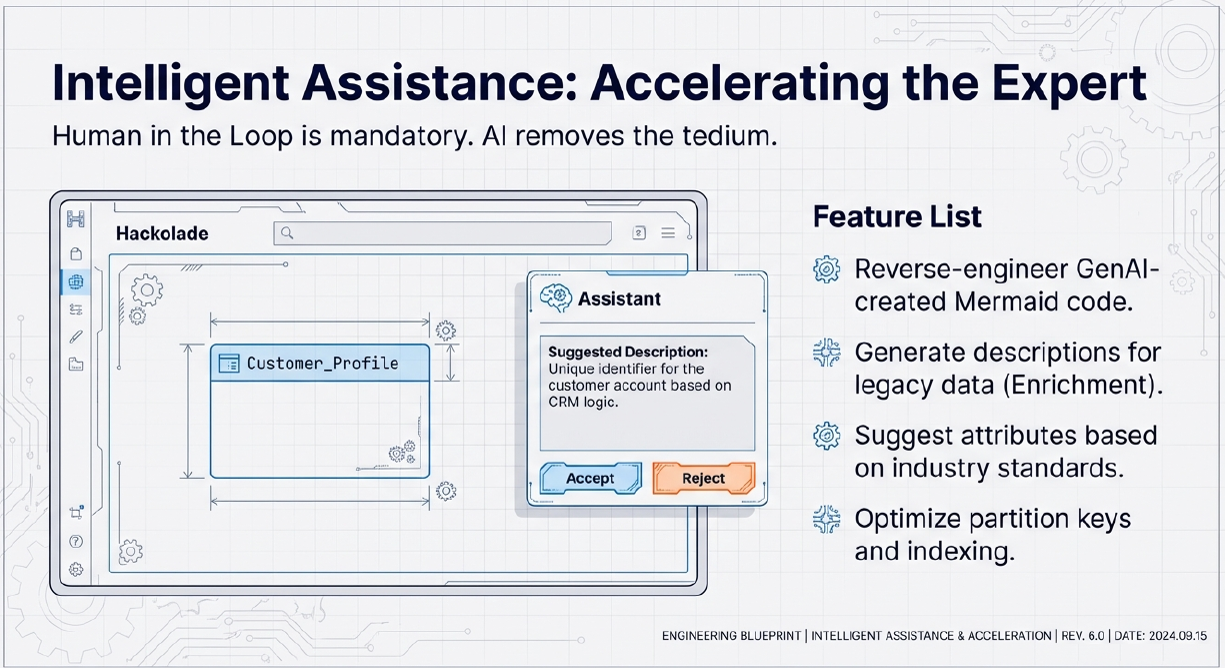
Currently on our roadmap, are the following features:
- Available: reverse-engineer Mermaid ERD code that could have been produced by GenAI in response to some prompt executed outside of Hackolade
- Still to be scheduled: use GenAI to create descriptions for selected entities and attributes of an existing model
- Use GenAI to suggest attributes for given entities, according to industry -specific standards
- Generate Mermaid ERD code from a Hackolade Studio model to be used in a GenAI prompt. Note that Mermaid has some limitations, such as lack of composite PKs/FKs, Not Null constraints, etc.
- Longer term: use GenAI to suggest an optimal dimensional model, given a transactional schema.
- Use agentic AI to suggest more optimal modeling, choice of partition keys, validate quality rules, ensure consistent naming and case, suggest indexes for read patterns or flag over-indexing in write-heavy patterns, identify breaking changes, etc..
- and more, based on customer feedback and suggestions.
Note that it is of course foreseen that any direct AI interaction from Hackolade Studio will be entirely optional for users, including that it could be disabled, if desired or if mandated by policy of the user's organization.
AI turns your static data models into living insights
Some organizations might treat data models as static diagrams: valuable but passive, locked away in repositories and accessible only to a limited few. Meanwhile, AI tools struggle to provide reliable answers because they lack grounding in the company’s actual data structures. Query building is laborious, reports leave room for interpretation, compliance checks are manual, and discovery across systems is painfully slow. The next leap in Generative AI lies in enriching LLMs with the semantics of private data -- not just exposing them to documents, but enabling them to understand and leverage the meaning embedded in that data securely. Techniques such as private Retrieval-Augmented Generation (RAG), AI Vector Search, and MCP (Model Context Protocol) servers allow organizations to infuse AI with private, contextual knowledge while maintaining confidentiality.
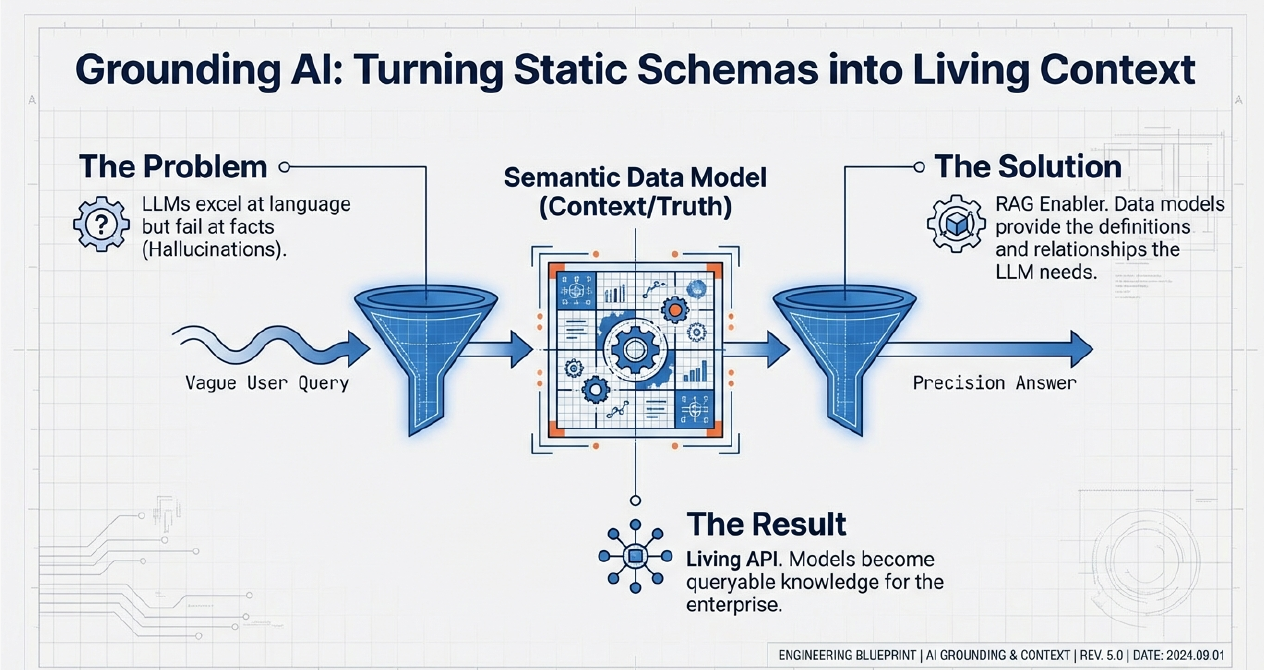
If you connect LLMs directly to your data without providing the semantics that explain the data, then LLMs, basing their reasoning on inference of meaning from table names and column names, are likely to come up with "plausible but wrong answers." Indeed column names rarely provide enough nuance and details about the column content. But data models contain rich descriptions, context and semantic meaning of the data. When the semantics of private data is made machine-understandable, data models become a live API for knowledge across the enterprise.
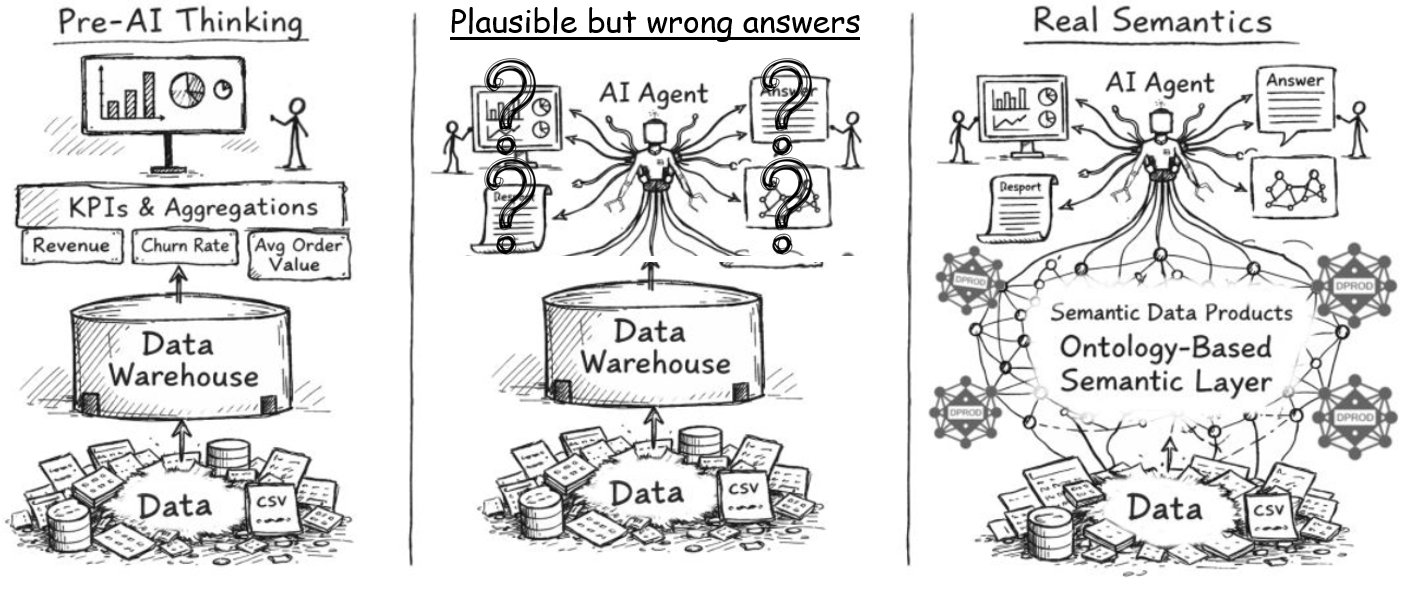
This semantic layer transforms raw information into an intelligent substrate that grounds AI in an organization’s real-world context. By exposing Hackolade Studio data models as queryable, living knowledge, enterprises can fuel automation, AI, and governance across SQL, NoSQL, graph, APIs, and cloud-native systems -- all from a single source of truth. AI assistants can now generate correct SQL and APIs because they’re anchored in real schemas. Compliance officers can ask direct questions and get instant answers. Analysts can discover data seamlessly across platforms. Architects can assess the impact of schema changes before they happen. In this model, data modeling evolves from documentation into an enterprise-wide intelligence layer -- accelerating work, ensuring compliance, and making the entire data ecosystem safer, smarter, and more agile.
Data modeling contributes to better AI
Developing an AI solution involves several iterative steps. The process begins with understanding the business problem and clearly defining objectives. Next, data is collected and explored to assess its structure, quality, and potential value, including identifying missing values, anomalies, biases, and uncovering patterns. The data is then prepared through cleaning and transformation, addressing issues such as incomplete data and bias. These early stages are supported by traditional data modeling practices: conceptual, logical, and physical data modeling that provide structure and context.
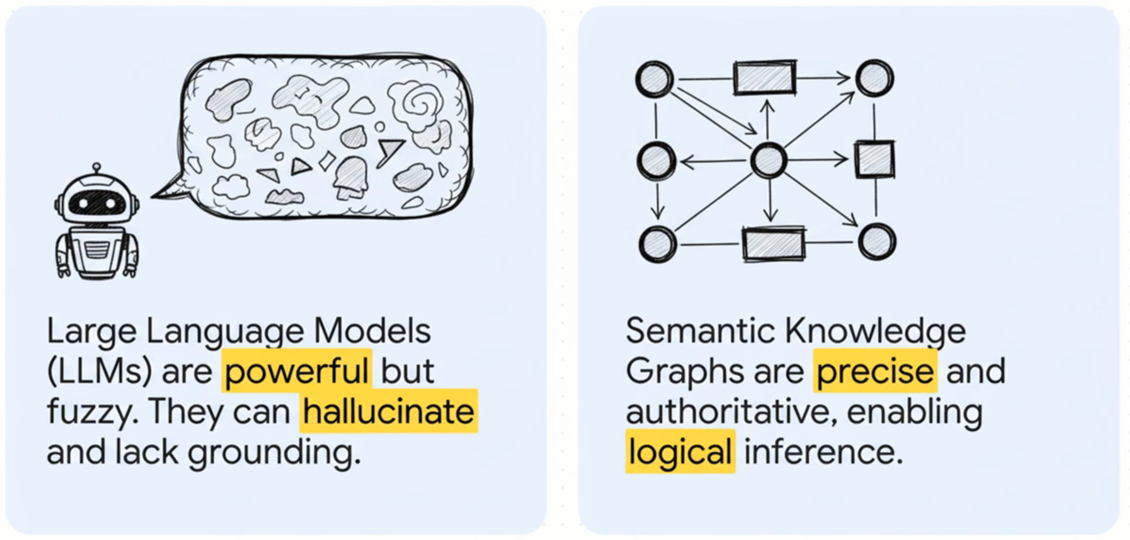
Good data modeling gives AI a high-quality foundation of clear concepts, relationships, constraints, and provenance. AI models learn and reason over clean, unambiguous signals instead of brittle, ad-hoc fields. Semantic knowledge graphs, defined using RDFS, OWL and SHACL, make structure machine-interpretable: classes and properties define meaning; axioms enable logical inference; SHACL guards data quality.
Large language models, meanwhile, are powerful but fuzzy; they excel at language yet hallucinate and lack grounding. Linking LLMs to a semantic knowledge graph turns text generation into grounded retrieval + reasoning: entities are disambiguated, answers cite authoritative nodes with lineage, and ontological rules constrain and validate outputs.
In practice, Knowledge Graphs provide the retrieval index and truth set; LLMs do natural-language interfaces, mapping questions to SPARQL/graph patterns, summarizing results, and drafting schema changes. The result is an intuitive and logical loop: the Knowledge Graph improves precision, consistency, and traceability; the LLM improves accessibility and productivity, together yielding safer, more accurate, and more maintainable AI.
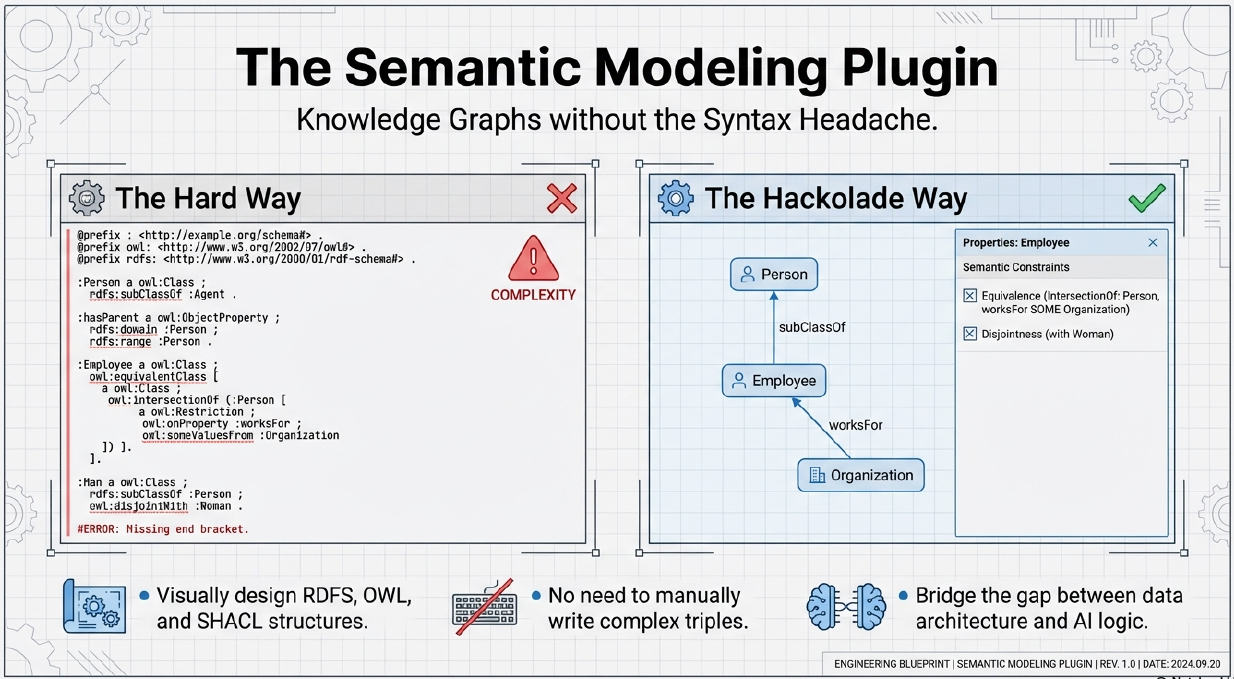
To make semantic technologies practical for everyday data professionals, Hackolade Studio is developing a semantic modeling plugin for its core visual data modeling engine. This plugin will allow data architects and modelers to design rich RDFS, OWL, and SHACL structures without writing a single line of syntax. Instead of editing complex triples or ontology files, users will simply define classes and their properties through familiar visual forms, setting relationships such as equivalence, disjointness, intersections, unions, and complements using intuitive checkboxes, dropdowns, and properties. Behind the scenes, Hackolade Studio automatically generates standards-compliant RDF/OWL/SHACL representations and validations, making advanced semantic modeling accessible to non-experts while preserving full technical rigor and interoperability with graph and AI ecosystems.
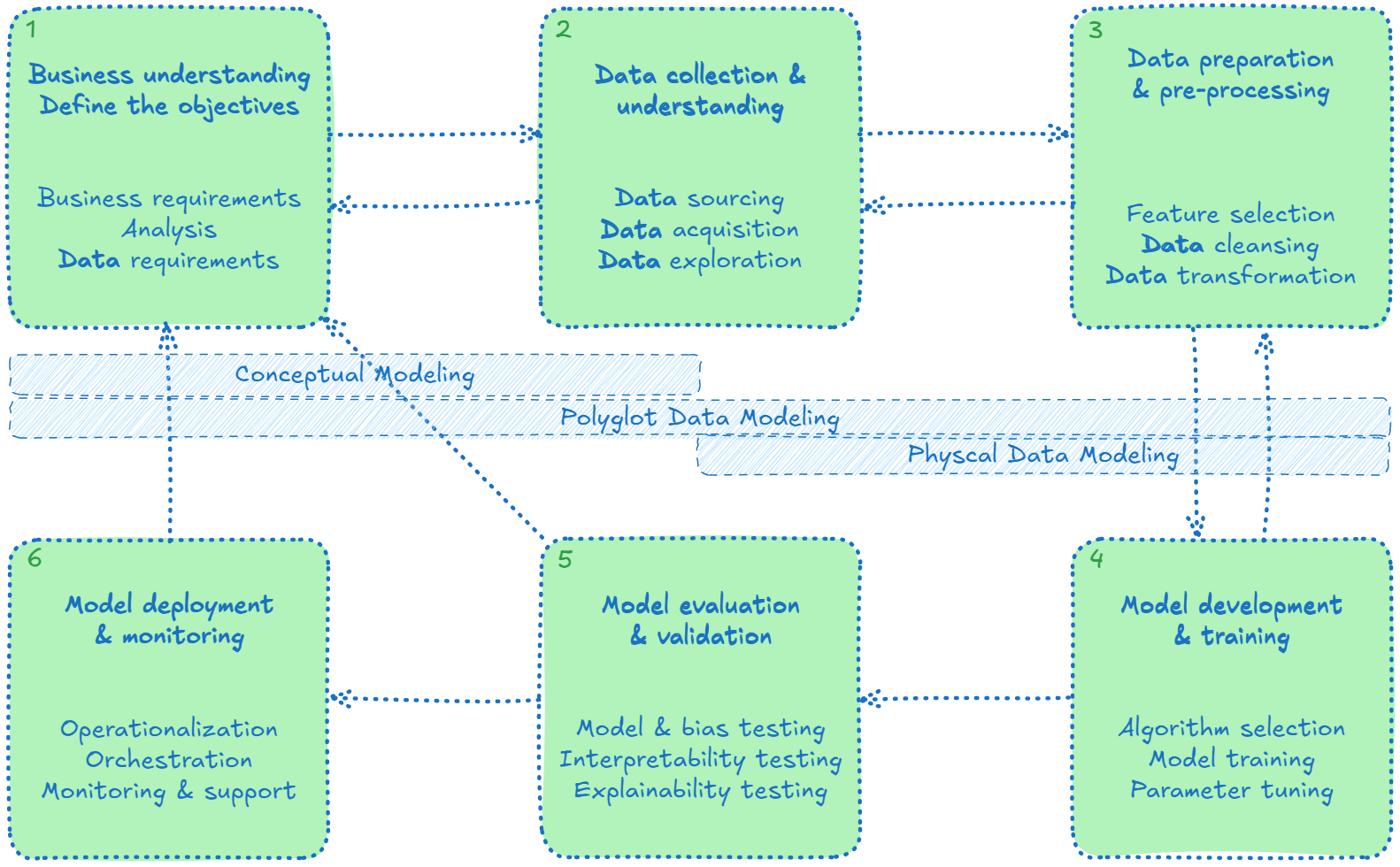
Diagram courtesy of Dave Wells dwells@infocentrig.org
This foundational work enables the development and training of algorithms using the prepared data. Model performance is then optimized through parameter tuning and evaluated using accuracy, precision, and alignment with business goals. Finally, the AI model is deployed in a real-world environment, where its performance is continuously monitored and refined in response to new data and feedback.
Data security and AI
An important factor to take into consideration is security. At Hackolade, we are very much aware of the legitimate security concerns of our customers. We want to make address these concerns by safeguarding private data, protecting access, providing guardrails to filter harmful content, and preventing leakage.
All AI-related features of Hackolade will be clearly identified as such, and will require specific opt-in to be activated by users. No data or information of customers will be used to train any of Hackolade's AI features or be transmitted by Hackolade outside of users' information technology environment without the user's express prior consent.
Data security in AI is a critical concern, as the rapid adoption of AI technologies introduces numerous risks to sensitive information. One of the major threats is the leakage of personal or confidential business data, where users of AI systems might inadvertently expose private details through their prompts, and AI systems their responses or models. Model inversion attacks are another significant risk, where adversaries can reverse-engineer AI outputs to uncover sensitive data used in training, potentially revealing confidential information. Data poisoning also poses a threat, where malicious actors intentionally inject misleading or harmful data into the training set, causing AI models to make erroneous decisions or behave unpredictably. Additionally, reliance on third-party AI services introduces the risk of opaque data access policies, where the service provider may have unrestricted access to the data being processed, leading to potential breaches or misuse. Furthermore, adversarial attacks, where small, imperceptible changes to input data are made to deceive AI models, could compromise the integrity of decision-making processes.
To mitigate these risks, it’s essential for organizations to implement robust security measures, such as data encryption, model transparency, and stringent access controls.
Running large language models (LLMs) on-premises is one of the most effective measures organizations can take to avoid data leakage. By hosting the models on their own infrastructure, companies can maintain full control over their data and ensure it doesn’t leave their secure environment. This approach helps mitigate risks associated with third-party AI services, where the data might be transmitted to external servers with less transparency regarding data handling and security practices.
On-premises deployment also minimizes the risk of data interception during transmission and offers better control over data access policies. Organizations can enforce stricter internal security protocols, such as encryption, network segmentation, and access restrictions, to safeguard sensitive information. Additionally, having LLMs on-premises means businesses can better monitor and audit model usage, ensuring compliance with privacy regulations (e.g., GDPR, HIPAA).
However, it's important to note that running LLMs on-premises also comes with its own set of challenges, like the need for specialized hardware, continuous maintenance, and expertise in managing these complex systems.
In any case, part of our AI roadmap is to take all these concerns into account, and always give the users the choice of how AI is being leveraged. Our pledge is to always ensure that Hackolade Studio users are always in control of whether or not AI can be used and, if used, how it is used.
In the book Agentic Design Patterns, Marco Argenti, CIO, Goldman Sachs shares the following thoughts which we found insightful and inspiring:
We must Build with Purpose, ensuring that every agent we design starts from a clear understanding of the client problem we are solving. We must Look Around Corners, anticipating failure modes and designing systems that are resilient by design. And above all, we must Inspire Trust, by being transparent about our methods and accountable for our outcomes.
In an agentic world, these tenets take on new urgency. The hard truth is that you cannot simply overlay these powerful new tools onto messy, inconsistent systems and expect good results. Messy systems plus agents are a recipe for disaster. An AI trained on "garbage" data doesn’t just produce garbage-out; it produces plausible, confident garbage that can poison an entire process. Therefore, our first and most critical task is to prepare the ground.
We must invest in clean data, consistent metadata, and well-defined APIs. We have to build the modern "interstate system" that allows these agents to operate safely and at high velocity. It is the hard, foundational work of building a programmable enterprise, an "enterprise as software," where our processes are as well-architected as our code.
Ultimately, this journey is not about replacing human ingenuity, but about augmenting it. It demands a new set of skills from all of us: the ability to explain a task with clarity, the wisdom to delegate, and the diligence to verify the quality of the output. It requires us to be humble, to acknowledge what we don’t know, and to never stop learning.